Large-scale astronomical high-cadence high-density pipeline with MonetDB
Today, astronomers are facing some of the hardest challenges working with petabyte-scale databases. Meng Wan, a researcher of the National Astronomical Observatories, Chinese Academy of Sciences (NAOC), has developed a data processing pipeline based on MonetDB for the Space-based multiband astronomical Variable Objects Monitor (SVOM) project [1], during her visit at the Database Architectures group of CWI. The pipeline is expected to store over 5 PB of data, while providing responses within seconds.
SVOM is a joint Chinese-French mission, aimed at studying Gamma-ray bursts (GRBs) [3]. The project consists of two segments: a satellite in the space to observe Gamma-ray, X-ray and visible lights, and a set of telescopes on the ground. To study the prompt optical emission of GRBs, NAOC is building a Ground Wide Angle Camera (GWAC) [2] — an array of ground telescopes pointing in the space in the same direction as the satellite. Since GRBs are often on very short time-scale, GWAC continuously observes a considerable part of the night sky. The main scientific goal of GWAC is to detect GRBs and extract transient sources. GWAC consist of 36 cameras on 9 mounts — 4 cameras each — taking pictures of the sky every 15 seconds during the nightly observations. The images expected to be captured amount to a total of 2.5 TB per night. The collected data is expected to reach 5.9 PB for the 7 operational years of GWAC.
The challenge for the GWAC data processing pipeline is two-fold: the system should be able to handle the constantly increasing volumes of data, while providing query responses in near real-time. The short response times are needed since GWAC is aimed at detecting short-lived transient events, such as GRBs. The GWAC light-curve processing pipeline needs to load the 36 sky images, analyse them and detect if new light sources have appeared, which indicate possible GRBs. Then, in the time frame of a few seconds of the event, both ground and space cameras have to be pointed at the new objects. What makes the task even more challenging is the high-density of light sources detected by GWAC — each image is expected to contain ~175,600 objects.
The high-cadence high-density pipeline looks like this:
- Light sources are extracted form the raw images and loaded into MonetDB. This happens every 15 seconds for each of the 36 cameras.
- Analytical functions in MonetDB compute source association with existing catalog information.
- Objects analysis and detection of transient events.
- The processed data are also stored in MonetDB for source classification and further data mining off-line.
To cope with the high-volume of data and high-cadance requirements, the system is partitioned into 36 worker MonetDB databases, one for each camera. A single master database server accesses all worker data using merge and remote tables, allowing for querying the data both individually and jointly. For further optimisation the data in each worker node are partitioned by time, keeping the chunk size evenly distributed. This partitioning is useful for astronomers, since they usually analyse the light sources in time slices. In its final form, including all optimisations, the system can process a 175,600 ×175,600 source association within 1.1 seconds. You can see below the results obtained in a comparison with PostgreSQL and PostgreSQL with a gist index.
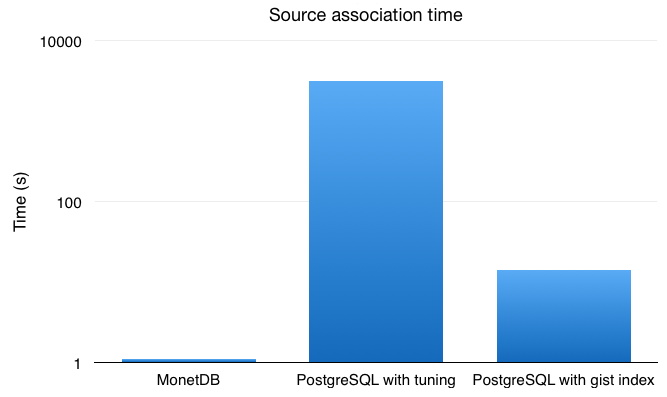
The MonetDB internal optimisations done for GWAC database have already been added to the sources code and most of them will be part of the July 2015 release. So is the initial sharding support with merge and remote tables.
If you are looking for further applications or data processing, once your data are stored in MonetDB, you can also try to extract more information out of it using the embedded Python/NumPy and R.
[1] SVOM
[3] Gamma-ray burst