Learning from Benchmarking
Development and maintenance of a new SQL database system involve benchmarks. They are based on a predefined data set and a collection of queries. Benchmarks are focussed on a particular application domain and can never replace running against an actual system/application. For example, the benchmark for online analytical processing and database research is TPCH.
The benchmark fulfils three significant roles:
Check functional working and SQL compliance
The SQL standard is elaborate. Sufficient for products is to support the core of the language ISO SQL. A new database offering is not well received in research and the market if it fails to perform well on a generic benchmark.
Explore the performance space
The benchmark may behave differently on scale factors. They are primarily used in research to identify and improve algorithms. Often a portion of the benchmark is used to focus upon.
Learn from each other
Given different workloads shed light on possible improvements in one’s database system.
In this short document, we document the lessons learned by comparing MonetDB and Clickouse. The code is made available in public repositories for others to bootstrap their experimentation.
MonetDB on Clickhouse
Clickhouse is a system developed by Yandex N.V. in the years. The application context is massive web-scale. MonetDB is developed at CWI as the pioneering column store. It is widely used for its analytical performance on multi-core, large main memories.
For many years Clickhouse published the results of running a DBMS against their data. It is the starting point for learning our lesson to improve MonetDB.
Architectural differences
Both systems’ architecture differs widely, making it an apples-orange comparison to isolate the features and choices leading to the performance numbers. In particular, Clickhouse storage layers are focused on Log-Structure-Files, a method where pre-sorting columns are the main road to achieving search performance. On the other hand, MonetDB storage layer is built around Binary-Association-Tables (BATs) and Straightforward C-arrays to keep the database in any order received. Clickhouse is focused on scale-out to many servers to handle PT-scale data. MonetDB is focused on the more modest database in a multi-core scale-up scenario.
- Lesson 0: SQL coverage is limited
The query set is heavily focused on aggregation tables over a single table. This limits the learning scope for MonetDB, which covers a broad SQL functionality. As a result, a few queries had to be slightly reformulated. They are available in the public repository MonetDB Clickhouse queries.
- Lesson 1: Sorting
The sorting nature in Clickhouse impacts the interpretation of design choice. To solve this, the database schema uses ordered indices in the MonetDB context to isolate the effect.
- Lesson 2: Shorter code paths
MonetDB contains an elaborate optimizer framework to translate SQL queries into its MonetDB Assemblee Language (MAL) plans. The MAL plans are executed by the kernel using parallel processing. Given the simple nature of the Clickhouse queries, we were able to reduce the code paths. Not only affects the Clickhouse queries, but also the performance on customer workloads characterized by simple SQL queries.
- Lesson 3: Alternative parallel processing
The benchmark illustrates the need for an alternative parallel data processing framework. One focussed on single table aggregation scans. This has been added to the database kernel without negatively affecting the performance of other workloads.
The slow queries identified in the jan22 release have significantly come down, not necessarily beating the clickhouse numbers. On simple queries (92-4, 20-23), MonetDB runs about 5x faster than Clickhouse. The new parallel code has properly addressed the outlier queries (29,37,39,40). The Clickhouse benchmark taught us a lesson. The modifications become available in the Jan23 release.
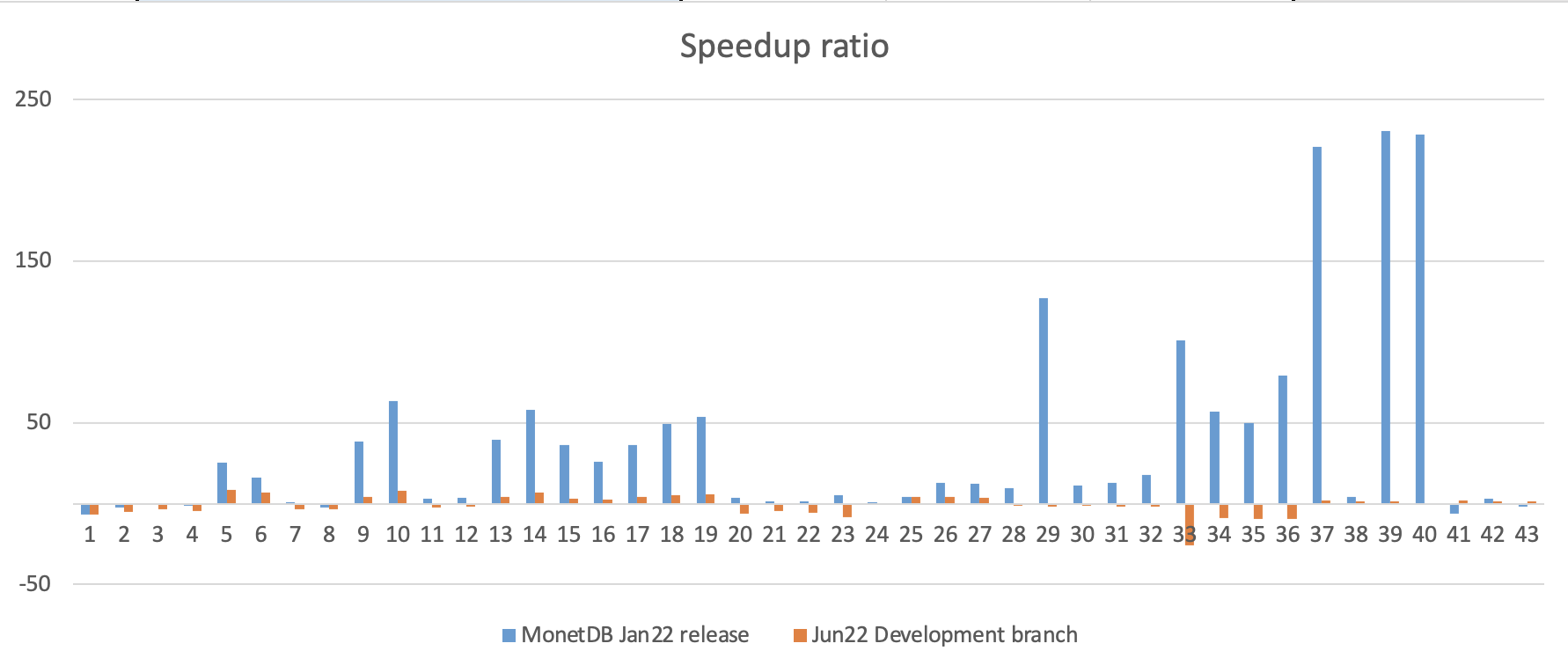
TPCH queries on Clickhouse
Although Clickhouse is not originally designed for TPCH workloads, understanding its behaviour in the workload will shed light on the remaining work to do. To aid users interested, we provide the Clickhouse variants of the TPCH queries. They are available in this GitHub repository.
SQL (non-) compliance
Clickhouse does not strictly follow the standard SQL syntax, and even some of the most straightforward features from traditional relational databases like Foreign Keys are not implemented. Besides, there is no support today for standard transactions with BEGIN/COMMIT enclosing. These features are used during the official SQL TPCH scripts to create the schema and add constraints. However, their system does have the ability to specify engines for databases and tables, and the default database engine is Atomic, which ensures non-blocking drops and renames from tables.
In fact, when you create a table, you may specify the ordering (which by default also establishes the primary key), but you need to define a Table Engine. This abstraction determines how and where data is stored, where to write it to, and where to read it from. It even affects which queries are supported or the concurrency level of query execution. By default, they recommend using the MergeTree engine, which is the most universal and functional table engine for high-load tasks. But there are more than 20 engines specifically designed to optimise certain query features like joins. This offers a high level of adaptation to specific applications but has the drawback of needing to know what kind of workload is your application facing and how to tune specific configuration parameters.
Translation of join queries
Even if Clickhouse recommends using a wide denormalized table and avoiding multi-joins as much as possible, they are supported in their system. The standard join clause works in queries as usual, even if sometimes it does not perform as well as expected. There are a few ways that the join clause can be optimised. The easiest ones are rewriting the JOIN with multiple IN clauses and creating external dictionaries to eliminate the small table in the join operation.
Besides that, a special table engine resides in-memory (backed up to disk on inserts) – the JOIN table engine. This allows the creation of a temporal table that can be reused, avoiding the expensive operation of creating hash tables for large operations that are repeated frequently.
Translation of subqueries
One of the main issues that had to be addressed to make TPCH queries work in Clickhouse was nested queries since the selected attributes in an outer query are not visible in the inner ones. This prevents many queries in the benchmarking suite from executing, especially those with WHERE conditions referencing attributes from outer queries. For instance in queries: 2, 4, 13, 15, 17, 20, 21 and 22. Most of these queries were rewritten using common table expressions, and some of them could be fixed by moving the referenced key of the inner query to the outer (using not in, instead of exists).
Many queries have issues when there is a float constant, or the result of an aggregation multiplied by Decimal columns of a fixed length. Clickhouse query engine does not support this operation straight away, so the only way to make them work is by adding casts toDecimal64. The affected queries were 11, 14 and 22, and they ran correctly after adding this change.
Tuning of the Clickhouse configuration
Some changes had to be made to experiment with Clickhouse. Some of the queries were taking a lot of time to run and the default timeout was preventing us from assessing if the queries were finishing or not. So the first change was increasing the default timeout writing in the client config file ~/.clickhouse-client/config.xml:
<config>
<receive_timeout>7200</receive_timeout>
<send_timeout>7200</send_timeout>
</config>
Besides that, another issue came up when executing queries with aggregations. After seconds of running, they were stopped due to trying to reserve more than 8GB of memory for the query execution. The problem was solved after:
- Increasing the max_server_memory_usage_to_ram_ratio from 0.9 to 2 in
/etc/clickhouse-server/config.xml - Tuning some of the client parameters on the queries that were having issues:
- set
max_memory_usage=40000000000; - set
max_bytes_before_external_group_by=20000000000; - set
max_threads=1;
- set
Clickhouse vs MonetDB
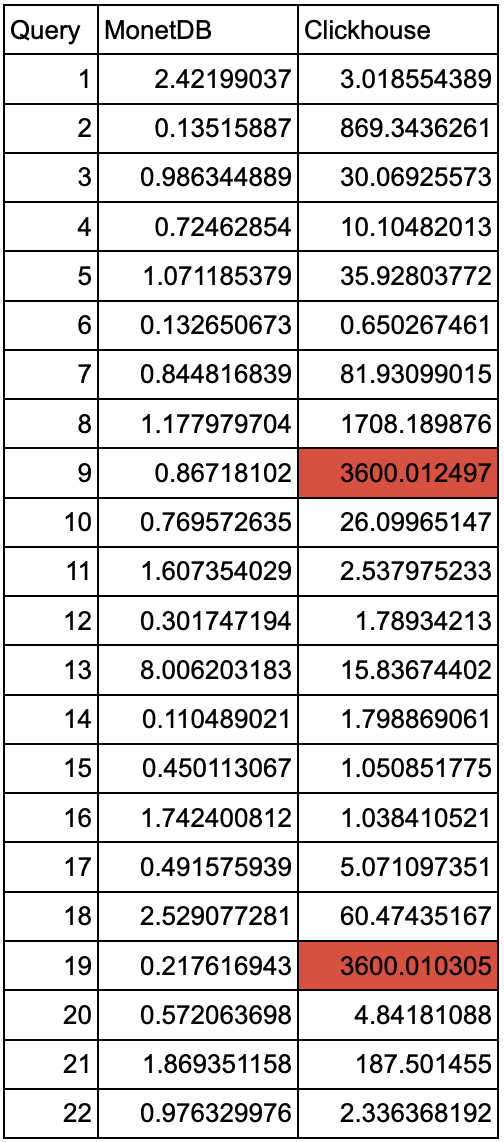
To assess the performance of Clickhouse and compare it with other database systems, we measured the execution time of the TPCH queries while running on a database with a Scale Factor (SF) of 30, which takes approximately 30GB on disk. In this experiment, we used a timeout of 1h since some of the queries were not finishing after multiple hours, even when using a lower SF (3). The version of Clickhouse was 22.1.3.7 and MonetDB (Jan2022-SP2), both obtained from their respective official docker repositories.
 |
|---|
| Figure 2: TPCH SF30 MonetDB vs Clickhouse |
As it can be observed, even if a couple of queries (1 and 16) perform on a similar scale, the general trend is that Clickhouse does not manage to keep up with MonetDB when executing queries from the TPCH benchmark suite. This might be related to the fact that TPCH performs many aggregation operations on big tables, which is one of the worst aspects of Clickhouse.
We measured the performance of another two DB systems, Postgres and MariaDB, using their latest version available on docker.io while running the TPCH query set for a Scale Factor of 30. If we compare the total execution time, Clickhouse is 272 times slower than MonetDB in running the whole TPCH benchmark set. However, Clickhouse has only 2 queries that do not finish (they reach the 1h timeout), the same amount as Postgres – which was 211 times slower. Both outperform significantly MariaDB, which has 6 queries that reach the timeout of 1 h and is 1035 times slower than MonetDB. It is worth noting that Clickhouse did take some parameter-tuning work, so the server did not crash due to being out of memory or bumping into default timeouts, while Postgres and MariaDB worked out of the box.
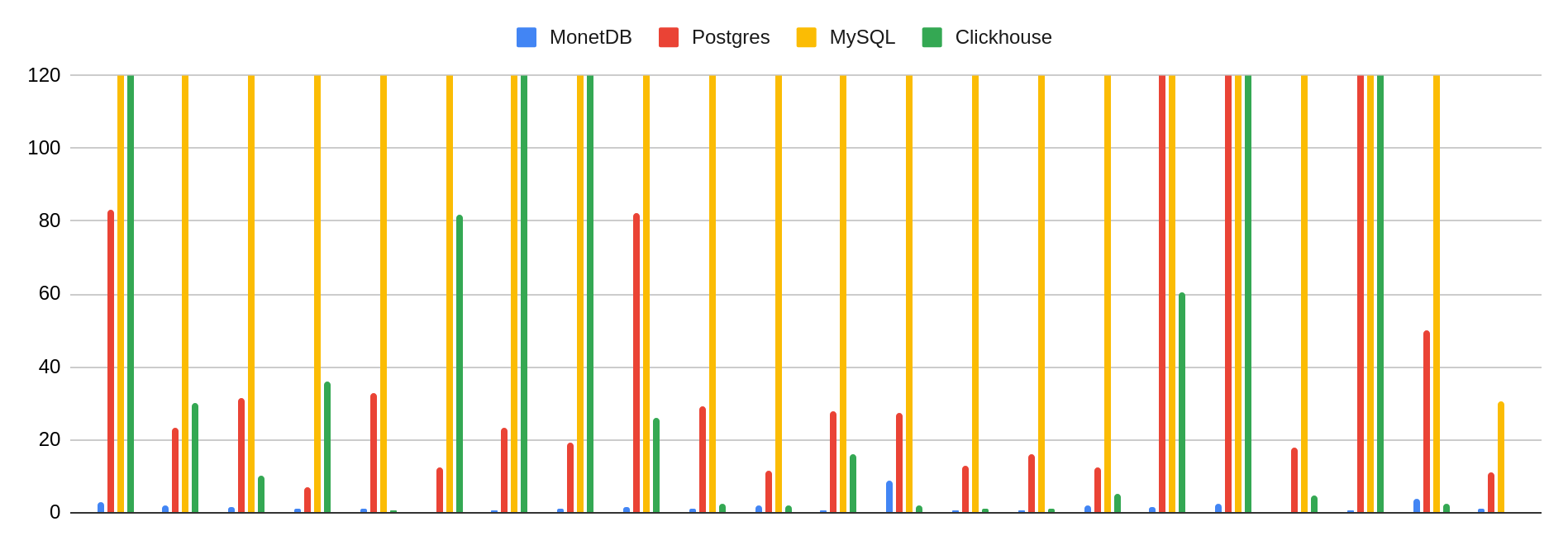
Comparing execution times of queries with such a wild difference is impossible to do. Still, in this chart, we can observe the general trend when zooming in and setting a maximum value of 120 seconds for the execution time (recall that some of the bars go up to thousands of seconds). The blue bars – corresponding to MonetDB – are so small that they are barely visible. Postgres and Clickhouse go hand in hand in execution time for most queries, outperforming each other on different occasions. MariaDB, labelled as MySQL (how its binary is still called), only has 1 query (22) with an execution time under 2 minutes, the rest quite longer than the other systems and 6 of them reach the 1h timeout limit.
 |
|---|
| Figure 3: Execution time comparison for TPCH SF30 |